encloud Confidential LLM Inferencing
Overview
encloud is a modular and interoperable software that enables organisations to deploy machine learning and AI like LLMs in a private, confidential and auditable manner.
These features are increasingly important as businesses move toward hybrid cloud architectures to optimise performance and cost of deployment. In such hybrid solutions, data is exposed to multiple threats unless a robust privacy solution like encloud is deployed. With the incoming AI regulation, privacy and security are not only critical to protect data and its inherent value, but a regulatory requirement.
To achieve the required privacy standards, encloud employs confidential computing (Trusted Execution Environment (TEE)/secure enclaves), AES256 encryption scheme, and encryption key release for valid environments and workloads
encloud will imminently release access to our beta product and have prepared a demo to share how LLMs can be leveraged for simple inference using the encloud confidential computing architecture with a pre-trained open-source model, Vicuna and its Fast Chat bot.
The demo workflow
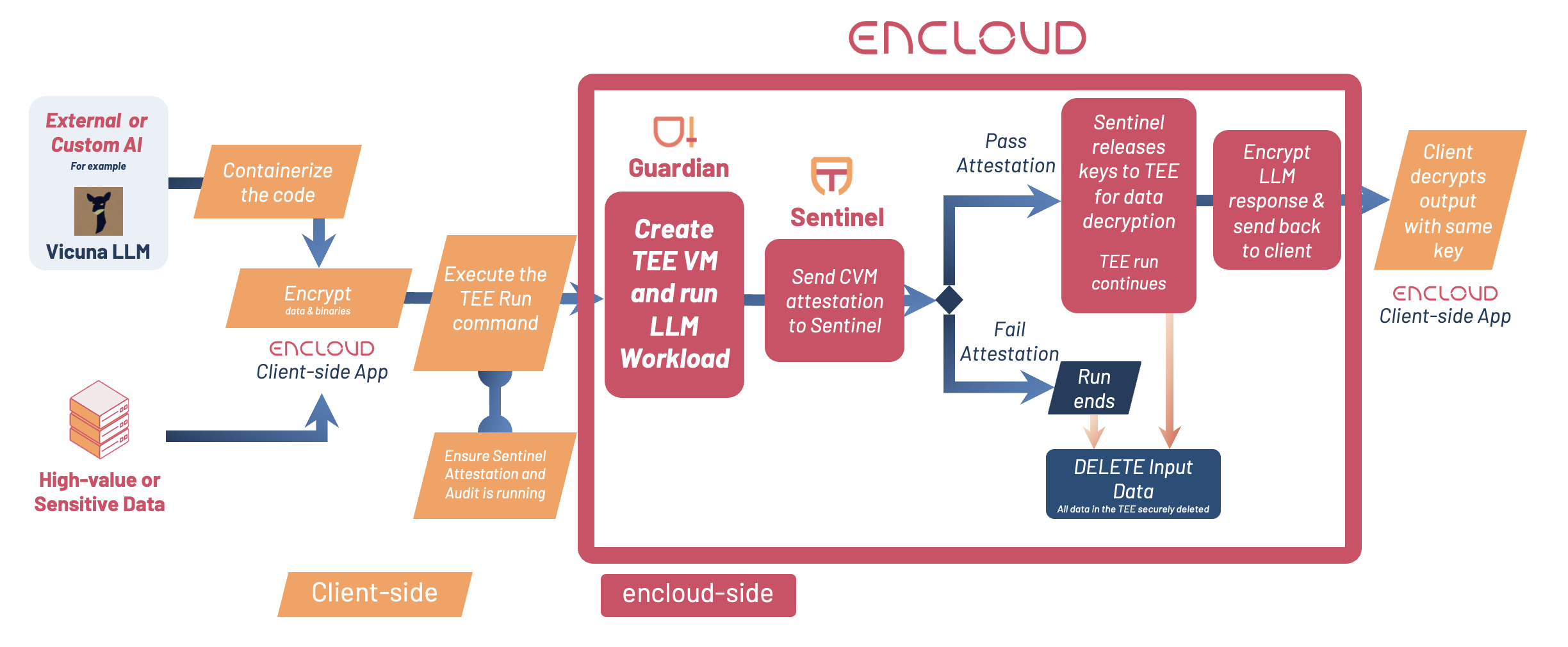
The workflow described below shows the end-to-end steps encloud takes at each step to manage and protect the data, LLM, and the interaction.
The process
To protect the data and AI, the developer will use the encloud client or other encryption software to encrypt the input data (using AES 256 GCM) and also leverage a publicly available LLM model (available on DockerHub) on the client side before it is sent to the cloud or hardware of their choice.
Once uploaded to encloud, if the Sentinel attestation report shows that the data, AI and the runtime environment (TEE) is not compromised in any way, Sentinel will release the keys for the data to be decrypted within the TEE. Note that decrypted inputs remain in the TEE environment where no parties can view or access the data – this includes the data owner and cloud administrators with the highest level of access. The outcome of the attestation will also be logged for auditability.
Once the necessary inputs are decrypted, the TEE will run the AI workload and gather the response from the LLM chatbot. The responses from the LLM are encrypted using the AES 256 DEK – using the same encryption key as the inputs. This ensures that the responses from the LLMs are also protected in-transit until it arrives at the client-side.
Post the completion of the compute operation, the TEE or CVM instance is destroyed and all inputs and VM state is deleted securely without any party gaining access to the inputs during and after deletion – ensuring privacy is maintained.
Summary
This demo shows how encloud can be used for a simple LLM inference workflow. Furthermore, encloud will be adding capabilities for more complex LLM workflows using confidential computing GPUs : 1) inferencing using embedding models, 2) LLM fine-tuning, 3) LLM training.
encloud will soon release the API for organisations to combine their high-value data with their AI workflows on trusted execution environments. If you would like to test encloud out and be notified of when the API is available, please register on our website (www.encloud.tech).